Are You Smarter Than 304 Matchboxes?
Since the release of ChatGPT in 2021, everyone and their dog have been hearing about AI. This has led to a lot of confusion amongst the general public since the terms AI, Machine Learning, and LLM are being used interchangeably. This past year I've been teaching younger audiences about AI with the education non profit Planète Sciences and I wanted to make a physical support that demystified "AI" in a fun way and could start the conversations on the different forms of AI systems.
So I recreated MENACE (Matchbox Educable Noughts and Crosses Engine), a mechanical AI built from 304 matchboxes and colored beads capable of learning to play tic-tac-toe, and eventually beat you to it.

I've first heard about MENACE on this Matt Parker video in 2018, this version was made by Matthew Scroggs, self-proclaimed "World's #1 matchbox fan". More about it on this blogpost. Though Matthew's version introduced me to MENACE, he did not come up with it himself.
The first version of MENACE was designed in 1961 by Donald Michie, a British computer scientist who's most famous for having helped break the German encryption during WWII. This idea came from a bet with a colleague who told him it was impossible to create a machine that could learn to play games. These days, it is common to get beaten by AI playing Chess, Go or even Mario Kart. But when Michie took the bet it was 13 years before computer even used mice and AI was still in its infancy.
Regardless Michie was convinced that it was possible to create such a machine. And after a while, this is what he came back with:

How MENACE was made
Accounting for all possible symmetries, there are 774 reachable board states in tic-tac-toe, if you don't count the boards where someone has already won. If you were to create a machine that would tell you what is the best move for any given board, you would need for each of these 774 board states to know what is the best next move. But if you were to play against this machine and let it make the first move, it'll "only" have to consider the 304 states where it is its turn to play.
So Michie asked around and got his hands on 304 matchboxes, each one representing a possible configuration of the board. To give MENACE the ability to say what move it wants to play, each box was filled with colored beads, each color representing a square on the board.
How to play against MENACE?
When it is MENACE's turn, you simply have to find the corresponding box (note that symmetrical configurations have only one box, so you need to imagine the possible rotations and update the board to match the box configuration).
Once the box is found, remove a bead at random and play the corresponding move, the box and the bead drawn are kept aside for the training phase. Once MENACE has played, it's the human's turn to choose his move. The operation is repeated until one of the players wins or the game is a draw.
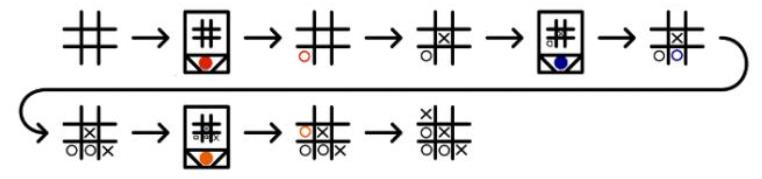
At first each box is filled with the same amount of beads to give each possible move the same probability.
How does MENACE learn?
After around 150 games played, the AI becomes unbeatable. This does not occur magically and MENACE needs to be trained on each game it plays to constantly improve by learning from its mistakes.
Once the game is over, there are three possible scenarios:
- MENACE has lost: the drawn beads are removed from their respective boxes.
- MENACE has won: we add 3 beads of the color drawn to each box.
- The game is a tie: 1 bead of the color drawn is added to each box.
This makes the losing moves less likely and the winning moves more probable. This is an example of the reinforcement learning algorithm, MENACE is one of its first implementations.
When Donald Michie first played MENACE in 1961, he played 220 games over 16 hours in one weekend. After just 20 games, MENACE was regularly drawing games.
These algorithms from the machine learning family enable AIs to learn to master complex systems without the need for real games as training data. For example, if two versions of MENACE were played against each other, they would both end up playing perfectly, even though neither of them has any idea of what they are doing.
In 2016, a version of this algorithm was used to create the AlphaGO AI, which beat the world Go champion for the first time ever. Today one of the most known applications of reinforcement learning is RLHF, which aligns language models like ChatGPT with human expectations based on user feedback.
Making my own version
I created my version of MENACE for the Planète Science Occitanie scientific education non profit.
First I computed the 304 possible configurations using a simple python script, accounting for all possible symmetries and impossible moves. I then conceived the design of the box for laser cutting and built it in around October 2024. To facilitate handling and find the right box, a web interface helping you find the correct box is available at https://rubengr.es/menace. It is also possible to view statistics on the current game. The box is currently being used in workshops and is improving over time. All the code and files used for this version are available on GitHub
What other games can MENACE play?
Tic-tac-toe is a perfect game for MENACE because there is a relatively small amount of possible board states. Other games having a similarly low amount of states (Nim being a famous example) can be solved easily by using the same methods.
For complex systems, modern reinforcement learning algorithms do not account for all possible configurations but use neural networks to approximate the state space.
But if you really wanted to create the Chess version of MENACE though, you'll need ten to the fortieth matchboxes and a whole lot of beads. Let's say you used the universal paperclip approach and mined a few planets for resources to make all matchboxes and beads you needed. This many matchboxes would start to collapse from their own gravitational pull and create a sphere spanning across the whole solar system.
Good luck finding your box then!
PS: A few details I left out for the more curious
After a few games, some boxes may be empty. If an empty box is found, MENACE gives up. It's possible that the first box empties quickly, so we'll have to reset the first boxes with more beads to give it more time to learn.
Before training, 4 beads of each color are placed in the first box. This is followed by three beads in the third-shot box, two in the fifth-shot box and a single bead in the last-shot box. This makes it possible to reward or punish the last moves more strongly, as they have a greater effect on the outcome of the game.