The Environmental Cost Of Training A Large Language Model
Recently I've been reading "Ralentir ou périr. L'économie de la décroissance" by Thimothée Parrique, an essay on degrowth and what it could look like. In his essay, Thimothée cites a 2019 MIT study that concluded that "Training a single AI model can emit as much carbon as five cars in their lifetimes"
Here is a figure from the accompanying article comparing common carbon footprints:
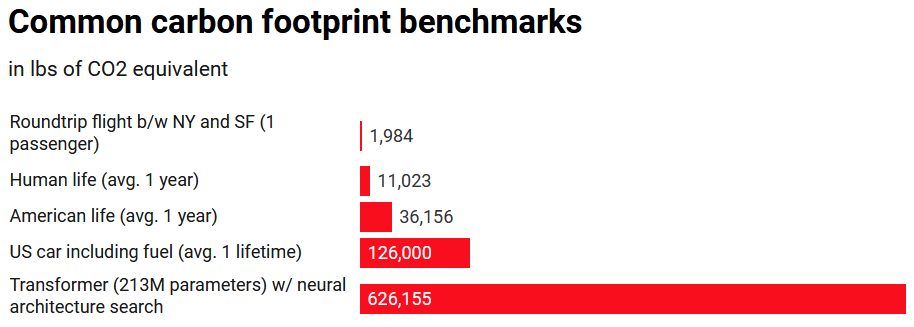
Wait a minute... five cars is not that much is it?
At the time, the study focused on GPT-2, the Large Language Model (LLM) that eventually became ChatGPT. Five cars isn't that much, how come Microsoft increased its carbon emissions by 30 per cent since 2020 and Google its greenhouse gas emissions (GHG) by 48 per cent since 2019 and blames it on ML? Seems like the rules have changed since 2019.
Now that we're in 2024 and the world is going through an AI craze, let's see how many cars it takes to train a state of the art language model.
Meta sells your data but shares its research
The metaverse didn't catch on...
When Meta finally admitted it, they went all in on AI and started making models to compete against OpenAI. Their strategy is a bit different though as they prefer focusing on use cases and distribute their model in open source, even allowing commercial use.
Anyone (or anyone with a good enough computer) can download the latest state of the art open source model, download the research paper and learn how Meta approaches building their LLM. Meta commitment to open source allow us to have some insight of what it take to train a stochastic parrot shoggoth in the post ChatGPT era.
So, let's do just that and find out how many cars it takes to train a single AI model... in 2024.
Llama 3.1 and its paper
The 23rd July, Meta released its new family of models in the Llama family. This new version, LLama 3.1 declines in three versions of different sizes and capabilities: 8B, 70B and 405B. ("B" roughly represents a billion neurons: the bigger, the better)
This new family of models arrived by storm in the LLM community, and for good reasons: it's the best open source model to date, rivalizing with the latest version of ChatGPT at the time of release.
But contrary to ChatGPT, the release came with a 92 page scientific paper going into great technical details into the training, alignment and testing process. It's detailed enough so that we can start to derive some numbers from there.
What we learn from the paper
The first two families of Llama models were trained on Meta's supercluster announced in January 2022, at the time it was comprised of 6,080 A100 GPU. But this supercluster was not enough for the new Llama models that were trained on a brand new 48k H100 GPU cluster
By the end of 2024, Meta aims to scale this supercomputer with the processing power of 600k H100 GPUs. (Guess why there is a shortage of NVIDIA GPUs these days?) If you were to buy all of these GPU yourself the total cost would be around eighteen billion dollars. EIGHTEEN - BILLION - DOLLARS. This represents a tenth of Meta revenues, and we're only counting the cost of the GPUs.
That sounds like it uses more than five cars, maybe we'll need a bigger garage...
Let's crunch the numbers
Of course all of the cluster is not used entirely at once. No more than 16k GPUs are used for training at any given time. According to nvidia, each H100 uses around 700W of electricity when in use.
The training lasted around a hundred days, which for 16k GPU is coherent with the 39.3M GPU hours in the paper. If we do a simple multiplication we can guess the number of Watt per hour that was poured into training Llama3.1
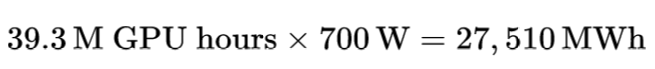
27,510 MWh! If we take the average US household energy consumption to have an idea of scale, training theses models uses enough electricity to cover the needs of ten thousand households for the 3 months it took to train the model, thirty thousand if these were french households.
Meta does not disclose the location of its training datacenter, let's compare what this would cost in different countries using the ElectricityMap website
| Country | gCO₂/kWh | Llama3.1 training in tons CO₂ |
|---|---|---|
| Sweden | 13 | 357 |
| France | 25 | 687 |
| Germany | 250 | 6, 875 |
| United States | 400-700 | 11, 000 - 19, 250 |
Realistically, this datacenter is probably in the United States, and if Meta made the effort to choose a state were the electricity is low carbon, 11k tons of CO₂ should be pretty close to reality.
Dr. Sasha Luccioni — who you should follow — posted a Linkedin post a few days after the model release that included a table for training CO₂ emissions. She arrived at a total of 11,390 tons of CO₂eq emissions, so my calculations aren't far off!
Going back to the figure for US cars in the beginning of this article, we can finally calculate how many cars it takes to train an LLM nowadays, using Sasha's estimation because I trust her more than me:
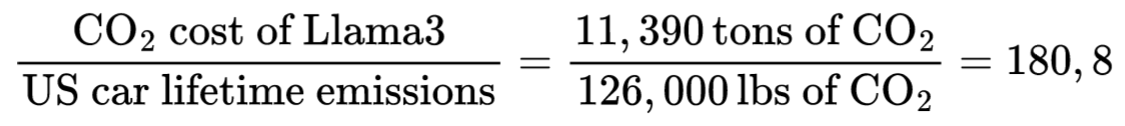
Finally, we can update the MIT Technology review article:
Training a single AI model can emit as much carbon as a
fiveone hundred eighty one cars in their lifetimes
So since 2019, training a state of the art Large Language Model is now 36 times more damaging to the planet, and accounts for a pretty big traffic jam.
Hidden costs and roadblocks
This figure is without counting the embodied CO2, i.e the cost of manufacturing the data center where this training has taken place. Nvidia does not currently disclose the carbon footprint of its GPUs but from an article by Sasha Luccioni et al. we estimate this cost to be about 150 kg of CO2eq / GPU.
For our 16k H100 this accounts for 2,400 tons more, assuming the carbon cost for building a GPU stayed about the same since this article was written (which it hasn't). These GPUs will be used for training other models so it's not obvious how to account for them in our calculations.
This isn't even accounting for the inference cost — the cost of running the model — that is way higher than the cost of training, and very hard to quantify.
The mere amount of electricity is not the only problem they face when building large language models, let's look at this excerpt from the paper:
During training, tens of thousands of GPUs may increase or decrease power consumption at the same time [...]. When this happens, it can result in instant fluctuations of power consumption across the data center on the order of tens of megawatts, stretching the limits of the power grid. This is an ongoing challenge for us as we scale training for future, even larger Llama models.
A major roadblock for the next generation AI is power consumption.
Meta is not the only one facing this issue as OpenAI wants to build 5-gigawatt datacenters. That's the output of five nuclear plants, for a single datacenter.
A solution would be to plug a dedicated power plant directly to the datacenter. We're starting to see some signs of this: Microsoft is refurbishing a nuclear power plant for their datacenters and Amazon is heavily investing in nuclear energy.
Or, you know, just crash the grid.

So, what do we do now?
GenAI isn't slowing down any time soon as LLMs start to appear in every product we use everyday.
Companies are in an arms race to build the biggest and most powerful model, but we still have a lot to learn from what we can do with our current ones. OpenAI recently released o1, which is not bigger but achieves better results by "taking the time to think" before answering. I believe approaches like this are promising in the near future to achieve better results with same sized models.
In the meantime you can try being conscious about your usage. For example, avoid going straight to ChatGPT when a simple google search would have done the job. And save a little bit of energy every time.
Or go all in and hope our AI overlords can solve our current life threatening global climate crisis.

Thanks to Philippe and Capucine for proofreading and catching math errors.